
I was perusing BookRiot yesterday and came across a post entitled “12 Alternatives to Goodreads.” This is a hot topic since the announcement that Amazon is acquiring Goodreads, and I found it interesting that Amazon has a stake in the first two alternatives listed (they own Shelfari outright and have a minority interest in LibraryThing). That, however, isn’t what this post is about.
One of the alternatives that BookRiot listed is a site called BookLamp. Most book sites that give recommendations are based on either bestsellers by genre, “people who read this also read that,” or social recommendations (“your friends liked this”). BookLamp takes a different approach that’s based on the Book Genome Project. Instead of looking at publisher marketing information, genre classifications, or social data, it analyzes the “DNA” of the books to look for similarities.
Why does this make a difference? Because every other recommendation site I’ve seen is heavily influenced by publisher marketing budgets and well-known authors. As an example, let’s say two authors write very similar books at the same time. Steve is a very well-known author with two bestsellers under his belt, and his books are published by Penguin — one of the big players. Bob is an unknown whose first book is being published by a tiny regional publisher.
Even if the books are equally well-written and have the same target audience, more of that audience will discover Steve’s new book. Some will already be fans of his, watching eagerly for his next release. Others will see the banner ads, well-made trailer video, and social media promotion. Most will remain completely unaware of Bob’s book. When you go looking for something new, you may see dozens of recommendations for Steve’s book, but none for Bob’s. Not because Bob’s isn’t as good; because nobody knows about it.
The BookLamp system completely ignores all of that. It analyzes everything from setting to pacing, not for the whole book but on a chapter-by-chapter (or even page-by-page) basis. Here’s it’s analysis of a favorite book of mine, Fools Crow by James Welch:
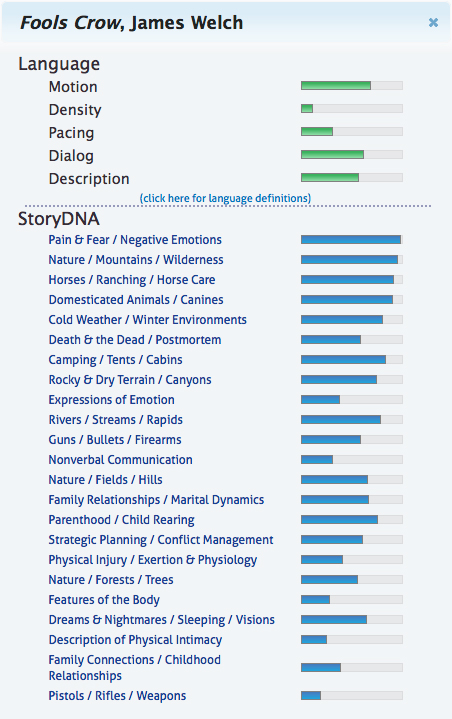
When I ask BookLamp for recommendations based on liking this book, it doesn’t try to shoehorn the book into a genre, look for other Native American writers, or take recommendations for friends. It looks for books that are set in the wilderness and involve horses, pets, parenthood, and visions. All of this data comes from computer analysis.
The analysis uses words and phrases to determine setting and topic focus. As an example, a book containing a lot of words like taxi, graffiti, elevator, and crowd is likely to be an urban setting. General characteristics like pacing and density come from formulas that have been around a long time, but have been refined by the Book Genome Project.
What this means is that BookLamp is likely to spit out recommendations that one wouldn’t get from GoodReads or Amazon—it’s the literary equivalent of the popular music site Pandora.

Their database is still rather limited. I tested it using some of my favorite fiction. They had Blind Your Ponies by Stanley Gordon West and Surely You’re Joking, Mr. Feynman! by Richard Feynman. They did not have Dancing at the Rascal Fair by Ivan Doig or Dodger by Terry Pratchett.
I don’t know that this will replace personal recommendations from friends, but it’s certainly a wonderful way to augment those recommendations and find some interesting new books that you are likely to enjoy.
